爬虫框架 - scrapy¶
架构图¶
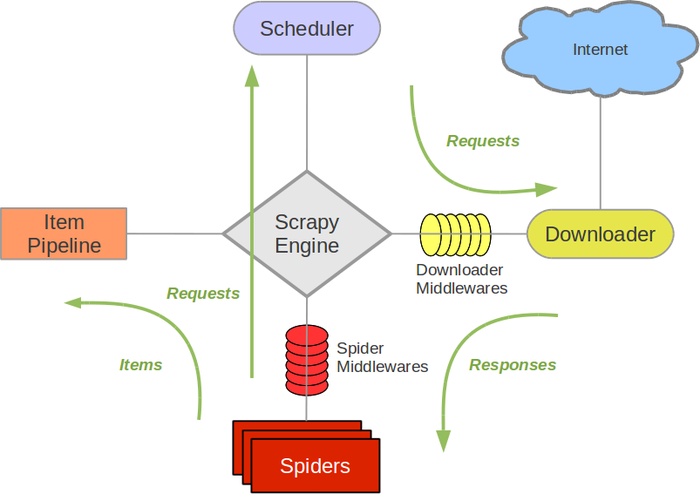
数据流向说明¶
scrapy引擎控制着整个爬虫的运行,引导数据到不同组件之间交流。大概步骤如下:[1] [2]
- scrapy引擎打开一个域名,同时分配爬虫来处理这个域名,并且告诉爬虫从第一个URL开始工作;
- The Engine gets the first URLs to crawl from the Spider and schedules themin the Scheduler, as Requests.
- scrapy引擎向调度器请求下一个URL
- 调度器返回下一个URL给scrapy引擎,scrapy引擎通过下载中间件将其发送给下载器
- 当一个页面下载完成,下载器会生成一个Response,并通过下载中间件将Response回传给scrapy引擎。(response direction)
- scrapy引擎收到来自下载器的Response后,通过爬虫中间件将其发送给爬虫进行处理;
- 爬虫处理完Response的数据后返回一个scraped项和新的Request给scrapy引擎;
- scrapy引擎将scraped项交给Pipeline进一步处理,将新的Request发送给调度器;
- 从第二步开始重复,直到调度器中的所有请求均被处理,scrapy引擎将关闭当前域名。